Nie&Gao
Anyway, life is elsewhere and we all know it.

「reordering」
Background
Intel 从8086系列芯片起到目前的Core i系列芯片,每一次提速与架构升级都会引入一些新的技术.指令重排序(instruction reordering)的概念大约出现在Pentium Pro系列上。在说明这项技术之前,先简单看一下CPU内部的组件与指令流水线等相关概念。
现代的CPU内部组织极其紧密与复杂(搞得好像我懂似的),为了简单起见(虽然简单,但是真实存在并且足以阐述问题),以最基础的80286为例,其内部逻辑抽象如下图所示:
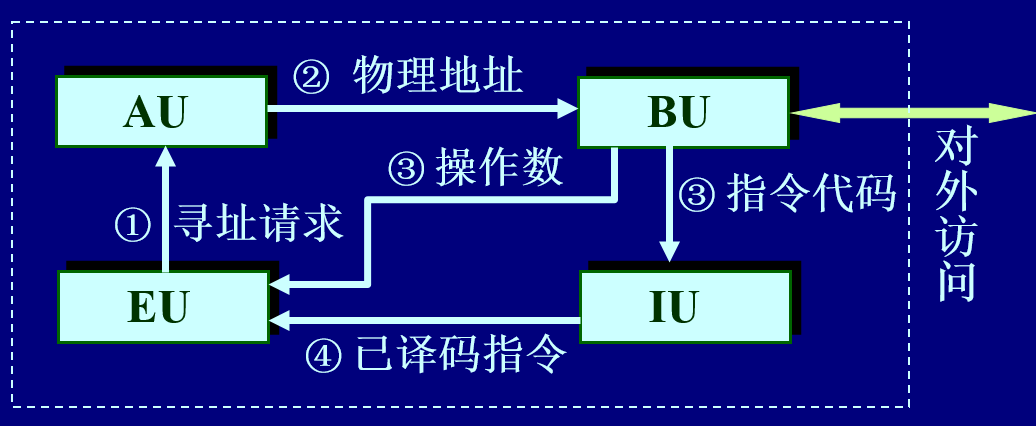
其中各部件的功能描述如下:
- AU 地址部件,主要负责根据寻址请求,生成物理地址
- BU 总线部件,主要负责内存物理寻址,完成数据传输
- EU 执行部件,负责执行指令要求的功能,包括运算器,微程序控制器等
- IU 指令部件,包含指令译码器和指令队列
任何用高级编程语言写成的程序都要最终由编译器,解释器等翻译成为CPU可以理解执行的指令。了解冯诺依曼体系结构的人都知道,无论我们的指令还是指令操作的数据,都是做为数据存在存储器里,在计算时输入计算器进行运算。所以,结合上图,完成一条指令就可以分为以下几个执行阶段,我们把完成一条指令所需要的时间称为:指令周期。
- 取指FE:发起取指请求,经物理地址转换和一次或者多次总线周期(视指令字长和总线位数而定),提取内存中的指令代码
- 译码DE:对指令代码进行译码
- 执行EX:由控制器根据指令编码,发送信号给执行部件进行计算(根据指令类型的差异,还可能需要多个总线周期读取操作数)
- 回写WB:将计算结果写到指定的目标地址上
这里插入一点关于指令周期,总线周期和时钟周期的知识:
 - 指令周期:CPU完成一条指令所需要的时间
- 总线周期:CPU通过总线完成一次内存或者I/O访问的时间
- 时钟周期:时钟频率的倒数,也就是我们买电脑时熟知的主频的倒数
- 指令周期:CPU完成一条指令所需要的时间
- 总线周期:CPU通过总线完成一次内存或者I/O访问的时间
- 时钟周期:时钟频率的倒数,也就是我们买电脑时熟知的主频的倒数
在多核技术出现以前,CPU通过不断提高主频,压缩时钟周期,让一条指令完成的时间更短,让我们用起来越来越快,但是受限于工艺,主频不会无限制的增长,但是CPU提速的需求没变,所以引入了多核,这也给编程人员如何充分利用这项技术,提升自己程序的性能带来了挑战。有兴趣的可以阅读The Free Lunch Is Over,中文版自行百度。
Pipeline
我们已经知道,我们的线程可以并行,数据可以并行,那么我们指令的执行为什么不能并行呢?在串行的指令执行方式下,一个指令周期只能执行一条指令,太慢了!为什么不能在对第一条指令译码的时候,就取第二条指令呢,在执行第一条指令的时候,再对第二条指令进行译码呢?假设,每个执行阶段都花费一个总线周期,在完美的条件下,那么我们的指令就可以以下图的方式运行起来,这就是指令流水线技术(大约在Intel 386里开始出现)。

在指令流水线的技术下,一条指令被拆分为多个独立的运行阶段,做个简单的计算,以前8个总线周期才能完成两条指令,现在我们8个总线周期就已经执行了五条指令了,效率提升了很多。
Instruction reordering
注意到,我们前面介绍流水线时提到了:完美条件。事实上,由于受到指令之间三种依赖的限制,我们的流水都没法完美的并行下去:
- 数据相关:后面的指令需要使用先前指令的计算结果
- 名相关:两条指令使用了相同的寄存器或者存储单元, 但他们之间又没有数据流动
- 控制相关:由分支指令引起的, 程序流向需根据分支指令执行的结果来确定。
指令重排序就可以用来解决数据相关,举个简单的例子,有如下三条指令:
ADD AX, BX; (1) AX + BX --> AX
INC AX; (2) AX + 1 --> AX
MOV CX, DX; (3) DX --> CX
按照前面介绍的指令流水线技术,我们会得到如下的执行效果图:
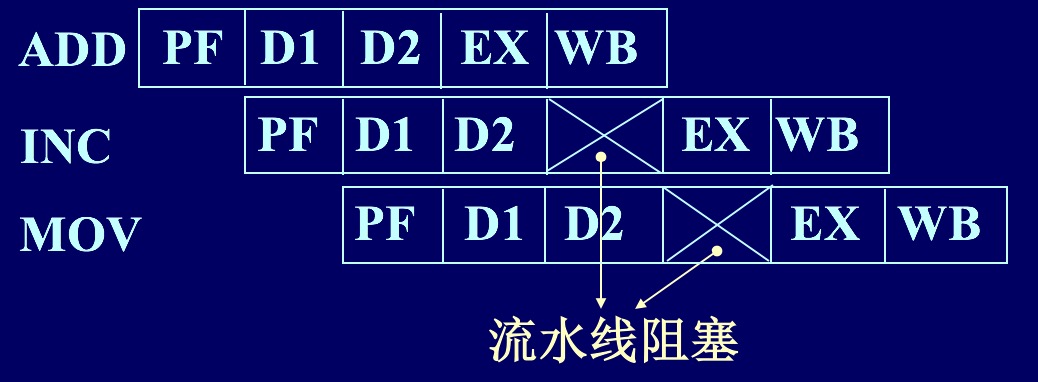
需要注意的是,上图为Pentium系列的5级指令流水线机制,PF 为指令预取周期,D1为指令译码周期,D2为地址生成周期,虽然指令周期的划分有变化,但不影响对流水线机制理解。由于指令(2)的执行阶段依赖指令(1)的执行结果,所以会出现一个时钟周期的空等待。但是指令(3)并不依赖指令(1)(2)的执行结果,所以可以通过对指令进行从排序,消除空等待,提升流水线的效率。下图是重排序后的指令流水线,不难看出指令的执行效率得到了提升。

当然,对于除了CPU可以对指令进行重排序之外,编译器也会进行适当的重排优化,并且编译器能进行的优化程度要高于CPU,因为CPU只能在局部指令范围内进行重排,而编译器可以全局的分析我们的程序。编译器进行指令重排也场景和规则比较复杂,有兴趣的可以研究一下。
Relevant things
指令重排序对程序开发人员来说,最大影响的就是多线程并发同步的问题。如果程序没有得到合适的同步,那么程序的运行结果将无法预测。
从硬件的角度来看,CPU与内存之间存在着数量级上的速度差异,为了充分利用资源,防止CPU空置,都会在二者之间加入片内缓存,毕竟访问片内缓存的速度要比通过总线访问内存的速度高很多。这给我们程序带来的影响就是我们可以充分利用缓存,提升效率,而当面临数据一致性问题时,就需要多加小心了。为了满足数据一致性的需求,CPU也提供了一些规则(内存屏障)和指令来支持强读内存(保证程序读取到的数值都是先前被修改过的值,而不是自己缓存的值)和强刷内存(保证程序对内存变量修改的全局可见性)。
多线程程序中,如果每个线程之间不需要交互,大家各自为政,互不干涉,自然相安无事,怕就怕有的线程之间存在共享的数据,由于存在重排序、内存分级,如果没有进行有效的管理,读写操作访问的位置和执行先后顺序的不确定性会严重影响程序最终运行结果的可解释性。
Java语言规范中通过内存模型限定了多线程并发时编译器和处理器的执行规范(顺序一致性原则和happens-before原则等),保证了在程序通过sychronized,volatile等关键字正确同步的情况下,多线程程序的全局一致性和各线程内的按照程序顺序执行。 所以,只要程序的最终运行结果满足此规范,无论虚拟机开发商以及处理器使用什么机制对程序和指令进行排序都是合法的。
关于Java内存模型更多的知识可以参考:Threads and locks, JSR133, JSR133FAQ, InfoQ博客
A memory model describes, given a program and an execution trace of that program, whether the execution trace is a legal execution of the program. The Java Memory Model describes what behaviors are legal in multithreaded code, and how threads may interact through memory.
At the processor level: a memory model defines necessary and sufficient conditions for knowing that writes to memory by other processors are visible to the current processor, and writes by the current processor are visible to other processors.
The compiler, runtime, and hardware are supposed to conspire to create the illusion of as-if-serial semantics, which means that in a single-threaded program, the program should not be able to observe the effects of reorderings. Most of the time, one thread doesn’t care what the other is doing. But when it does, that’s what synchronization is for.
Synchronization ensures that memory writes by a thread before or during a synchronized block are made visible in a predictable manner to other threads which synchronize on the same monitor. After we exit a synchronized block, we release the monitor, which has the effect of flushing the cache to main memory, so that writes made by this thread can be visible to other threads. Before we can enter a synchronized block, we acquire the monitor, which has the effect of invalidating the local processor cache so that variables will be reloaded from main memory.You have to set up a happens-before relationship for one thread to see the results of another.